Umgang mit fiktiven Daten
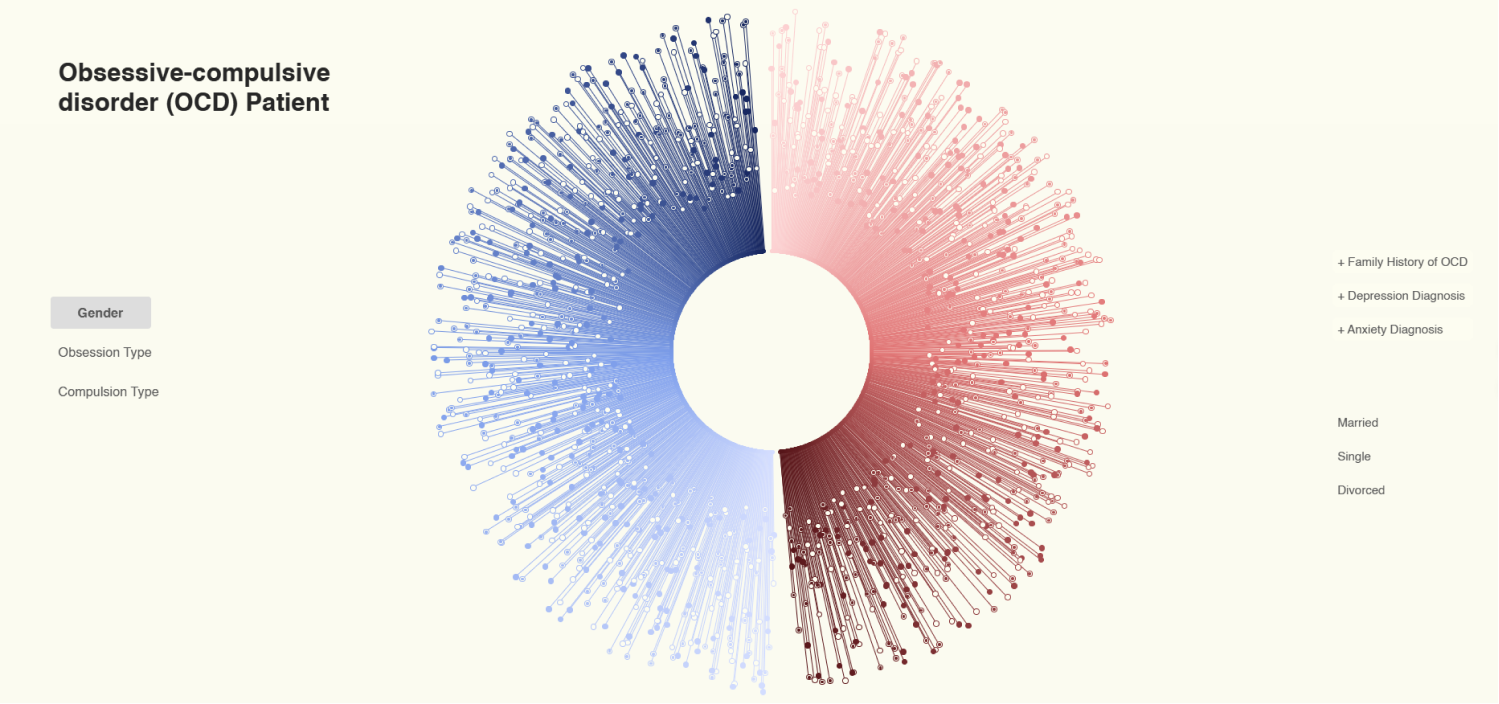
Die ursprüngliche Visualisierung des Datensatzes von Kaggle zeigte eine sehr gleichmäßige Verteilung, was auf die fiktiven Daten zurückzuführen ist. Diese gleichmäßige Verteilung entsprach nicht den realistischen Verhältnissen, die für eine anschauliche Darstellung erforderlich sind.
Um dieses Problem zu beheben, habe ich die Daten modifiziert, um eine gleichmäßige Verteilung zu vermeiden. Dazu habe ich ein Python-Skript entwickelt, das die Anteile der Daten durch prozentuale Anpassungen erhöht oder reduziert hat.
Optimierung der Visualisierung
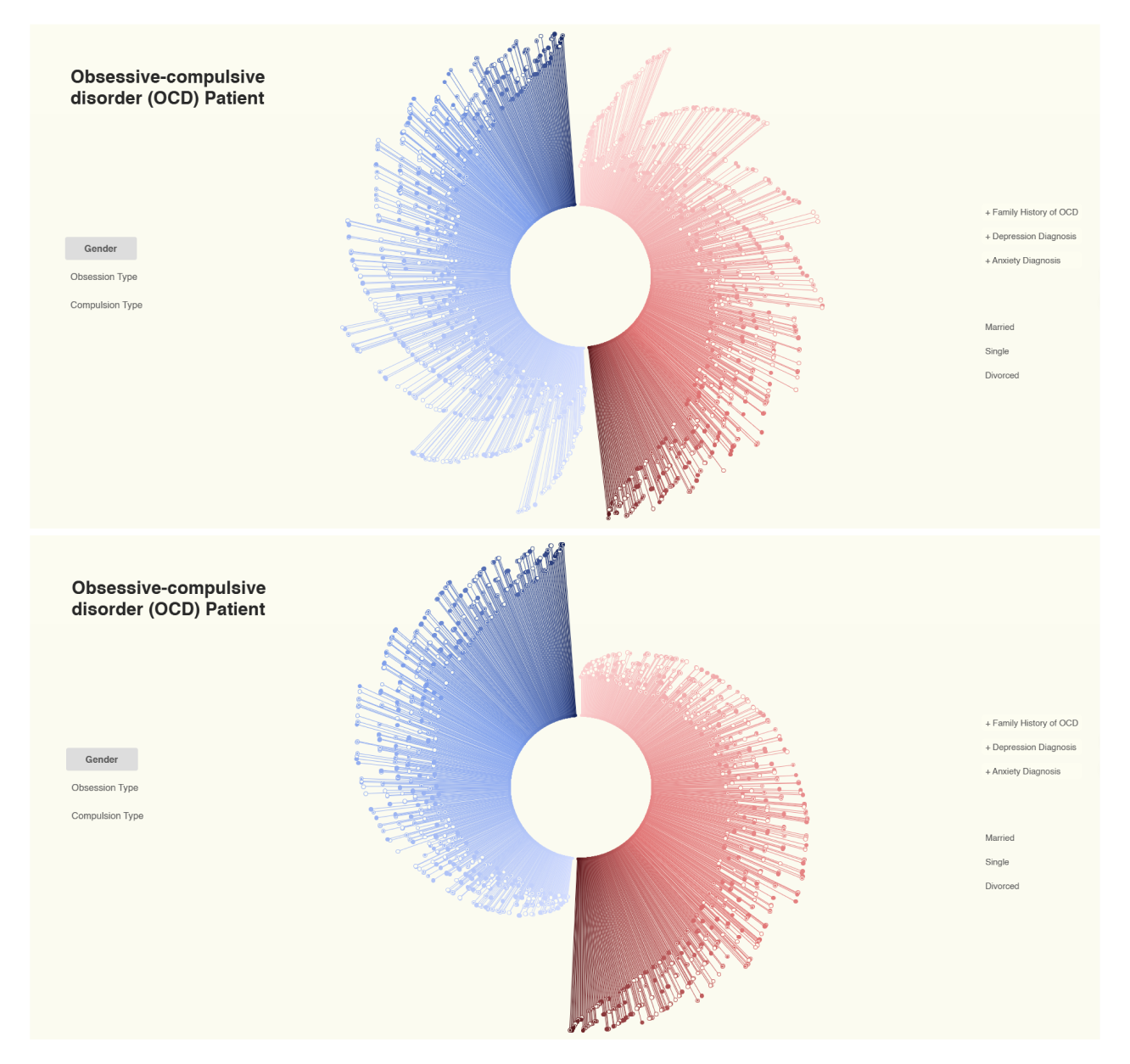
Hier sind zwei Möglichkeiten dargestellt, wie die Visualisierung nach den anfänglichen Anpassungen aussehen könnte. Dennoch wirkte das Ergebnis noch zu berechnet und nicht ausreichend anschaulich. Mein Ziel war es, die Darstellung so zu gestalten, dass hellere Farben tendenziell kürzere Linien und dunklere Farben längere Linien repräsentieren.
Finalisierung der Darstellung
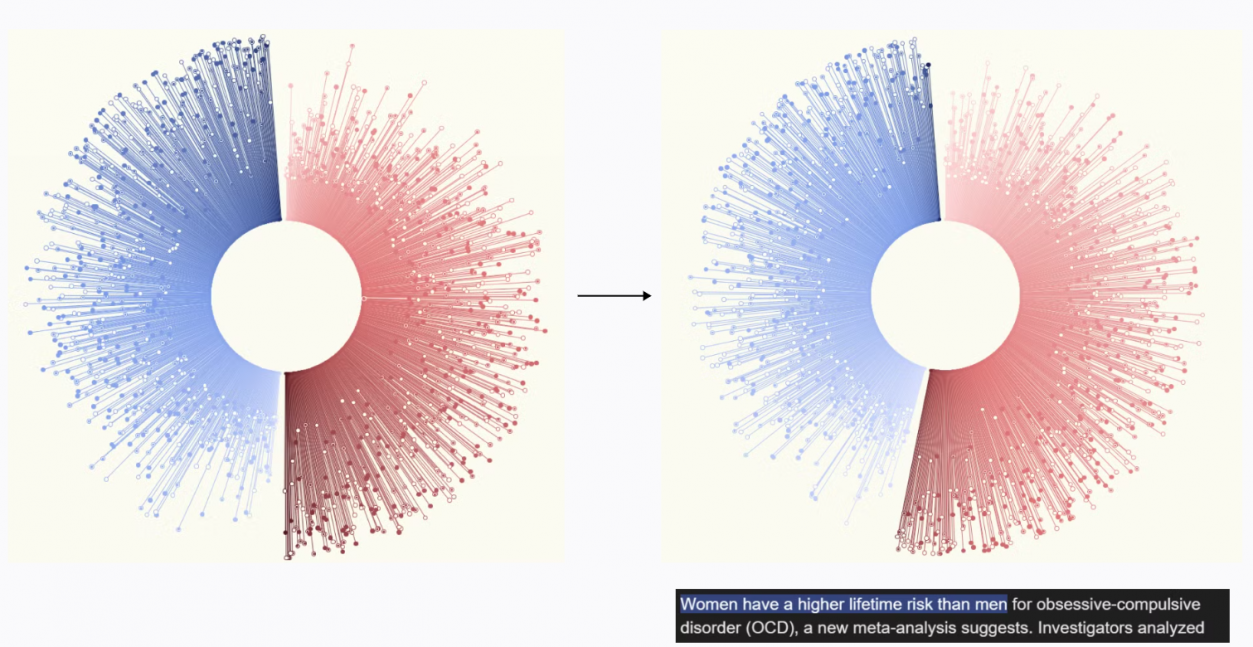
Hier ist die Darstellung, die ich ursprünglich erreichen wollte. Dennoch war der Anteil der dargestellten Daten zu gleichmäßig verteilt. Um dies zu verbessern, habe ich recherchiert, ob es einen signifikanten Unterschied zwischen den Geschlechtern bei der Häufigkeit von Zwangsstörungen gibt. Auf Basis dieser Erkenntnisse habe ich die Visualisierung angepasst, um die Unterschiede zwischen Frauen und Männern deutlicher darzustellen.
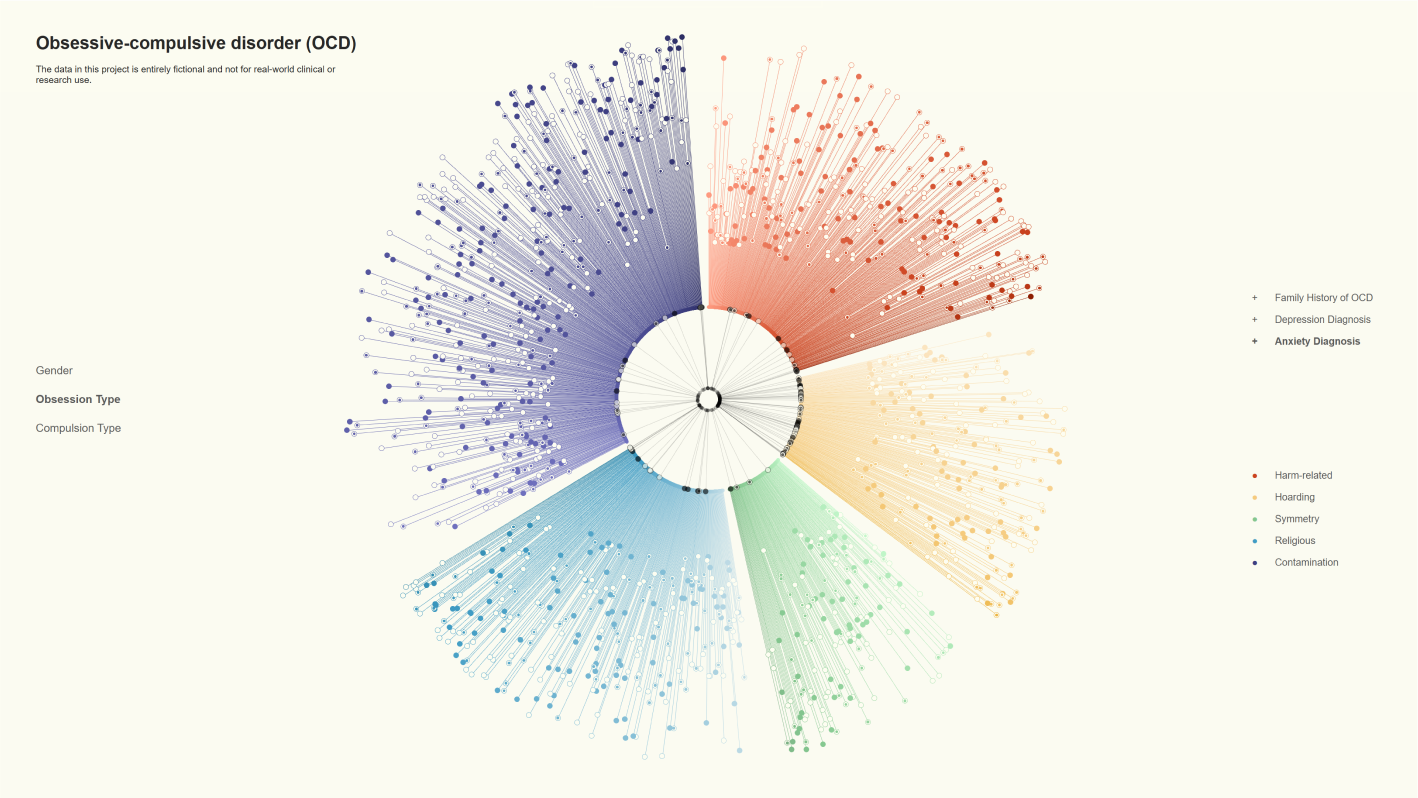
Ich habe auch bei anderen Ansichten ähnliche Anpassungen vorgenommen. Beispielsweise zeigt sich, dass Menschen, die von Hoarding betroffen sind, häufig auch unter Depressionen und Angststörungen leiden, in einem höheren Maß als bei anderen Typen.